An Empirical Evaluation of DP GANs for Social Science
Abstract
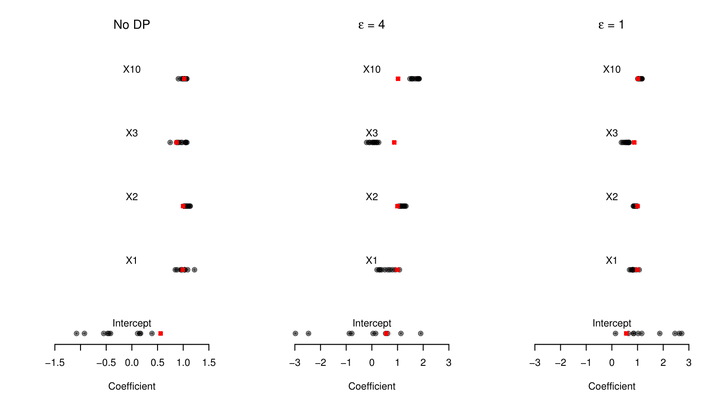
Political scientists pervasively use data that contains sensitive information – e.g. micro-level data about individuals. However, researchers face a dilemma while data has to be publicly available to make research reproducible, information about individuals needs to be protected. Synthetic copies of original data can address this concern, because ideally they contain all relevant statistical characteristics without disclosing private information. But generating synthetic data that captures–eventually undiscovered–statistical relationships is challenging. Moreover, it so far remains unsolved to fully control the amount of information disclosed during this process. To that end differentially private generative adversarial networks (DP-GANs) have been proposed in the (computer science) literature. We experimentally evaluate the trade-off between data utility and privacy protection in a simulation study by looking at evaluation metrics that are important for social scientists, specifically in terms of regression coefficients, marginal distributions and correlation structures. Our findings suggest that on average, higher levels of provided privacy negatively affects the synthetic data quality. We hope to encourage inter-disciplinary work between computer scientists and social scientists to develop more powerful DP-GANs in the future.