Dr. Sebastian Sternberg
Senior Data Scientist // Data Science Consultant
KPMG Wirtschaftsprüfungs AG
Biography
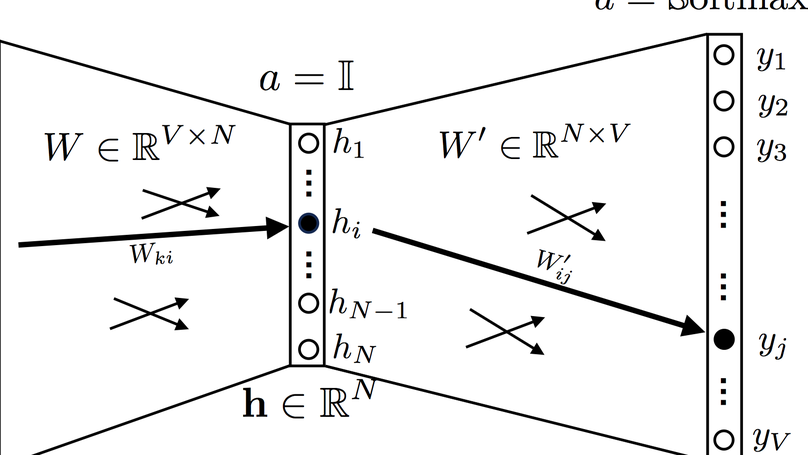
I am a Senior Data Scientist working at KPMG Lighthouse, KPMG’s Center of Data & Analytics in Germany. I mainly work on Natural Language Processing (NLP) topics, especially on information extraction from documents, e.g. invoices, contracts or form sheets. I also like to serve as a translator between non-technical stake-holders and the tech team.
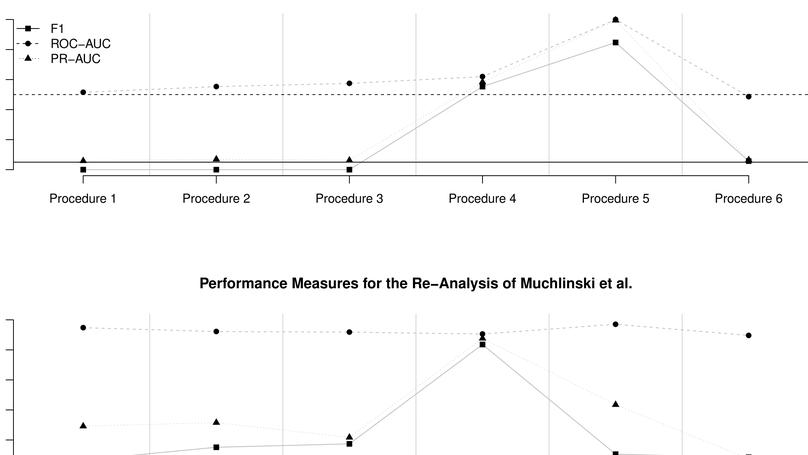
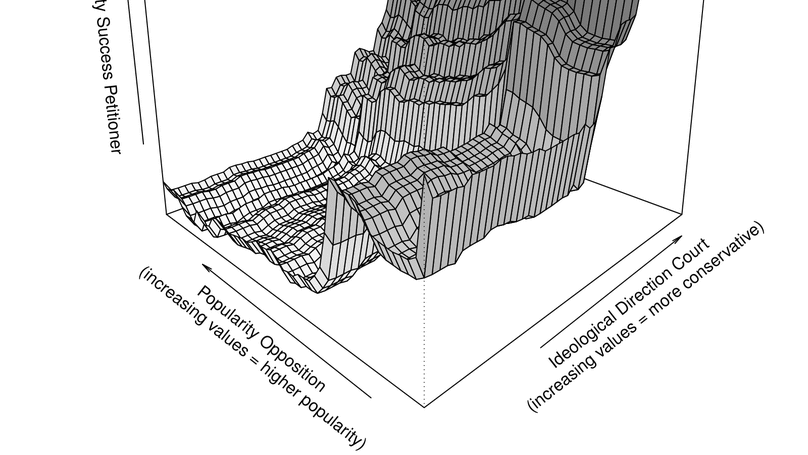
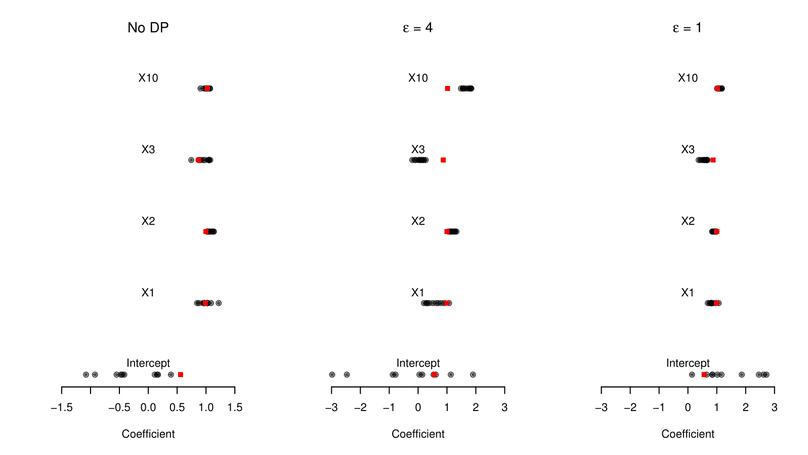
Before, I completed my PhD in 2019 at the Graduate School of Social Science and Economics at the Chair for Quantitative Methods at the University of Mannheim. During my PhD, I mainly worked on the application of machine learning approaches to political science questions, with a particular focus on predictive modelling and text analysis, e.g. predicting constitutional court decision-making with machine learning and measuring vagueness in judicial texts.
- Natural Language Processing
- Machine Learning
- Information Extraction
-
PhD, Chair of Quantitative Methods, 2019
University of Mannheim
-
Double Degree MA Public Administration, 2015
University of Konstanz & Science Po Grenoble
-
BA in Political Science & Public Law, 2013
University of Mannheim
Professional Experience
Responsibilities include:
- Team lead NLP
- Information Extraction using NLP from documents (OCR, machine learning, rule-based methods)
- Text classification using machine learning
- Stake-holder communication and PMO
- DevOps, Git, Kubernetes
- Python, R
Responsibilities include:
- Teaching statistic classes for undergraduate and graduate students
- Doctoral thesis title: No Public, No Power? Analyzing the Importance of Public Support for Constitutional Review with Novel Data and Machine Learning Methods
- Publication of the Year Award for paper “How cross-validation can go wrong and what do to about it”
- Presenting results at international conferences